KV数据库学习笔记
KV数据库学习笔记
项目背景
1.为什么会选择开发corekv
运行TESTApi
go test -timeout 30s -run ^TestAPI$ github.com/hardcore-os/corekvpackage corekv
import (
"github.com/hardcore-os/corekv/utils"
"testing"
"time"
)
func FuzzAPI(f *testing.F) {
//添加种子语料,必须和闭包西数的模弼参数一一对应
f.Add([]byte("core"), []byte("kv"))
clearDir()
db, _ := Open(opt)
defer func() { _ = db.Close() }()
//运行fuz2引学,不断生成测试用例进行测试
f.Fuzz(func(t *testing.T, key, value []byte) {
e := utils.NewEntry(key, value).WithTTL(1 * time.Second)
if err := db.Set(e); err != nil {
t.Fatal(err)
}
//道询
if entry, err := db.Get(key); err != nil {
t.Fatal(err)
} else {
t.Logf("db.Get key=%s,value=%s,expiresAt=%d", entry.Key, entry.Value, entry.ExpiresAt)
}
iter := db.NewIterator(&utils.Options{
IsAsc: false,
})
defer func() { _ = iter.Close() }()
for iter.Rewind(); iter.Valid(); iter.Next() {
it := iter.Item()
t.Logf("db.NewIterator key=%s,value=%s,expiresAt=%d", it.Entry().Key, it.Entry().Value, it.Entry().ExpiresAt)
}
t.Logf("db.stats.EntryNum=%+v", db.Info().EntryNum)
//除
if err := db.Del(key); err != nil {
t.Fatal(err)
}
})
}go test -parallel 1 -fuzz FuzzAPI1.1 拥抱云原生
1.1.1云原生的特点
- 计算与存储分离,计算节点保持少状态,甚至无状态;什么叫无状态-CSDN博客
- 基于日志的进行持久化;
- 存储分片/分块,易于扩容;
- 存储多副本与共识算法;
- 备份、恢复、快照功能下放到存储层。
- 要求云产品需要提供一定 “弹性”(Elastic),又要求云服务有一定的 “自愈”(Resilience)能力。
1.1.2 go语言的优点
- 语法简单
- 具有优秀的并发性能
- 适合做基础架构(如网络服务和系统工具)
1.2降低成本
1.2.1 为什么要降低成本
随着互联网业务的发展,数量量越来越大,全部存储到内存中的成本已负担不起,并且内存kv集群规模的增长也导致内存kv可用性的降低(节点崩
溃丢数据频繁发生),集群节点数据迁移等运维成本几何式增长。
1.2.2 corekv如何降低成本
市面上常用redis做kv数据库,但redis是纯内存数据库,适用于对延迟敏感,数据量小的业务
1.3保证业务的高缓存命中率
Redis作为内存数据库,其存储容量是有限的。如果缓存数据的容量超过了Redis的限制,就会导致缓存数据无法全部存储在Redis中,从而降低命中率。解决此问题的办法通常是增加Redis的内存或采用分布式缓存方案。
1.4分布式数据库方案
要开发一个分布式数据库,市面上没有太好的针对大value设计的存储引擎,rocksDB.是c++写的,我们的分布式数据库想要拥抱云原生,使用纯go开发,如果使用rcoksDB开发,需要使用cg0来调用,这会导致内存无法被有效管理等等极高的风,险,因此我们需要手写一个纯g0实现的kv引擎,更好的支持云原生数据coding。
项目目标与评估
目标:设计并实现一个高性能、低成本、高缓存命中率的分布式持久化kv引擎
LevelDB 对于数据量过大又对延迟要求高的场景,相较于 Redis 具有以下优势:
1. 更快的读取速度
LevelDB 使用跳表作为其底层数据结构,跳表是一种平衡二叉树,可以实现 O(log n) 的读取复杂度。而 Redis 使用哈希表作为其底层数据结构,哈希表可以实现 O(1) 的读取复杂度,但当数据量过大时,哈希表的性能会下降。
2. 更低的内存占用
LevelDB 的数据存储在 SST 文件中,SST 文件是一种紧凑的二进制格式,可以节省大量的内存空间。而 Redis 的数据存储在内存中,当数据量过大时,Redis 会占用大量的内存空间。
3. 更高的可靠性
LevelDB 使用 WAL(Write-Ahead Logging)机制来保证数据的可靠性,WAL 机制可以确保数据在写入磁盘之前先写入日志文件,即使发生系统故障,也可以从日志文件中恢复数据。而 Redis 使用 RDB(Redis DataBase)机制来保证数据的可靠性,RDB 机制会定期将数据保存到磁盘上,但如果在 RDB 保存期间发生系统故障,可能会导致数据丢失。
4. 更适合于大规模数据存储
LevelDB 非常适合于大规模数据存储,因为它可以将数据存储在多个 SST 文件中,并且可以对 SST 文件进行压缩,从而节省大量的存储空间。而 Redis 虽然也可以存储大规模数据,但当数据量过大时,Redis 的性能会下降。
5. 更适合于高并发场景
LevelDB 非常适合于高并发场景,因为它使用多线程来处理读写请求,并且可以对读写请求进行并发控制,从而提高系统的吞吐量。而 Redis 虽然也可以支持高并发,但当并发量过高时,Redis 的性能会下降。
测试写入1000条数据
--- PASS: TestAPI (2.87s)
PASS
ok github.com/hardcore-os/corekv 2.878s测试跳表写入一亿条数据
Benchmark_ConcurrentBasic-32 1000000000 0.005844 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/hardcore-os/corekv/utils 0.114s技术方案
1.项目架构

2.与Redis的对比
3.与leveldb的对比
技术要点
1.为什么corekv在内存结构中只有跳表(同leveldb),不像Redis一样支持多种数据结构?
coerkv的设计初衷是是实现高性能和可扩展性,它只使用跳表作为其内存结构,这使得它非常高效。
2.为什么有了go的GC,还要引入内存管理?
在CoreKV的应用场景下,处理的是大量的KV键值对的插入和删除。操作系统分配内存需要借助系统调用,并且陷入到内核态,这需要带来额外的上下文切换耗时,尤其是在频繁的插入操作中,少量的内存申请需要大量的切换开销,这样的操作带来的性能影响很大。虽然Golang已经帮助我们解决了内存分配的问题,但是Golang的内存分配是不区分业务逻辑的,只要程序有需要申请内存,Golang都会满足,这也就造成了Memtablel的内存可能和CoreKV代码的其他变量使用连续的内存空间。在Memtable这种需要频繁申请内存的地方,如果混杂着其他的申请请求,很可能导致内存碎片的产生,从而影响分配的效率和空
间的利用率。
简单来说,是:频繁申请、释放内存需要时间成本,且容易产生内存碎片
3.内存池是如何设计的,有什么优化方案,与leveldb中的内存池有何差别
有3大要点:
1.延迟释放:这和leveldb中的思路相同,都是Arena 在其生命周期内不会释放任何分配出去的内存,直到整个 Arena 被销毁时才一次性释放所有内存。
2.内存申请和分配:
leveldb中按块管理内存,将内存划分为固定大小的块,默认情况下每个块的大小为 4KB。且连续分配,当请求内存时,Arena 会在当前块中寻找足够大的连续空间来满足请求。策略是:当申请的内存大于剩余且大于四分之一块时,会分配新块
corekv中,不分块,采取翻倍增加的策略,最大为max(128M,申请大小)
3.内存对齐:思路相同,在skipList中有数据写入时都会进行内存对齐
- 跳表在设计过程中有哪些优化
1.利用面向对象的语言特点(接口),对数据库中的条目进行了封装
2.c++ 实现内存管理,直接操作即可。而由于go的特点,如果要避开go的GC,自己实现高性能的内存管理(结合要点2),只能预先申请一个大数组,在大数组中存储内存的所有数据结构,所有的操作都是用数组中的地址和偏移量的形式实现跳表,不能像c中一样用传统的操作指针的方式简单的实现跳表。也正因为此原因,kv的所有写入和读取前后都要有编解码的操作,代码就会略显复杂
3.在leveldb和Rocksdb中,当插入一个跳表中已有的key时。其用的是assert,确保不允许插入重复的键值。而在我们的kv中选择就地更新。这就增加了判断key的代码,这就需要在插入逻辑中有搜索的逻辑,就会影响性能,也会多出许多代码。但我们选择不追求极致的性能,而追求功能的完整性。
5.项目里为什么要用布隆过滤器,设计过程中的难点
布隆过滤器拥有k个哈希函数,当一个元素加入布隆过滤器时,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在维数组中把对应下标的值置位1。
判断某个数是否在布隆过滤器中,就对该元素进行k次哈希计算,得到的值在位数组中判断每个元素是否都为1,如果每个元素都为1,就说明这个值在布隆过滤器中。
在本项目中,有2个地方用到了布隆过滤器:
1.用在缓存模块,快速判断某个数据是否存在于缓存中
2.用在LSMTree中,快速判断某个key是否在SST文件中
当然,布隆过滤器未命中不代表不存在,未命中后还需要进一步具体查找
设计过程中,优化的点有:
- 测试了多个哈希函数的性能,选取了效率较高的一个
- 优化了布隆过滤器的工作过程
要控制函数个数使误判率最低,且保证性能。需要选一个适当的哈希函数,提高布隆过滤器的性能。而且使用duoblehash算法也能极大提升性能
实际的工作原理是:也就是通过两个哈希函数进行k次运算,得到k个 新哈希函数 ,再做k次运算 达到k次哈希的效果。这样只用到一次随机种子,降低了hash的假阳性,极大的提高了性能。
首先采用的MurmurHash的哈希生成策略就是:循环处理输入字节数组中长度大于等于 4 的部分,将每 4 个字节转换为一个 32 位整数,并累加到哈希值 h 上。
对 h 进行乘法和位运算,以增加哈希值的随机性。而代码中也是把每次的哈希值h通过``h>>17 | h<<15生成一个新的整数 , 并累加到哈希值h 上。这就等于一个全新的哈希值,且它没有用到seed` 相当于一个更简单的哈希函数,这样就相当于满足了论文中的理论条件,且计算量更低,性能更高。
6.缓存部分有什么优化,是如何提高命中率的
在设计缓存系统时参考了Caffeine(Java本地缓存中间件)中的算法WindowTinyLfu .在了解LRU和LFU后,我们希望结合2种算法的优点。
第一步,要改进LFU。1.LFU 需要大量空间来统计频次信息(哈希计数) 2.LFU 存在高频旧数据长期不被淘汰(保鲜机制),为此引入Count-Min Sketch(即为一个二维bit位图)。且我们认为缓存中一个 key 被访问 15 次即作为高频数据,那么我们利用 4 个 bit 位来标记一项数据,进一步压缩空间。这就是TinyLFU。
TinyLFU也有缺点:在对同一对象的“稀疏突发”的场景下,TinyLFU 会出现问题。在这种情况下,新突发的 key 无法建立足够的频率以保留在缓存中,从而导致不断的 cache miss。
第二步:我们希望结合LRU和TinyLFU,这样既可以很好的维护一个小的时间维度中,突发的高频率热点 又可以维护一段时间内突发的热点数据还要做到缓存保鲜。
具体实现:将缓存分为两部分,主缓存和窗口缓存。主缓存(main cache)使用 SLRU 逐出策略和 TinyLFU 接纳策略,而窗口缓存(window cache)采用 LRU 逐出策略而没有任何接纳策略。主缓存根据 SLRU 策略静态划分为 A1 和 A2 两个区域,80%的空间分配给热门项目(A2),并从 20%的非热门项目(A1)中挑选 victim。所有请求的 key 都会被允许进入窗口缓存,而窗口缓存的 victim 则有机会被允许进入主缓存。如果被接受,则 W-TinyLFU 的 victim 是主缓存的 victim,否则是窗口缓存的 victim。
7.对于不同情况的热点数据,缓存是如何做优化的?
对于历史热点数据(指从segment-lru的20% Probation(缓刑)区淘汰出的数据):
我们有 cmSketch 计数器,可以统计下过去的访问频率,做下比较,就能决定抛弃哪个了。
对于近期热点数据:
若访问的缓存数据,已经在 StageTwo(A2或Protected) ,只需要按照 LRU 规则提前即可。若访问的数据还在 StageOne,那么再次被访问到,就需要提升到 StageTwo 阶段了。StageTwo 中淘汰的数据不会消失,会进入 StageOne。 StageOne 中,访问频率更低的数据,有可能会被淘汰
如果大量的数据都只访问一次:
那么每次从 wlru 中淘汰的数据,会频繁的被淘汰出来,那么每一次都要跟 slru 中的做对比,因此我们引入了布隆过滤器,进行拦截。
总结:
针对只访问一次的数据,在 LRU 中很快就被淘汰了,不占用缓存空间。
针对突发性的稀疏流量,就是可能在短时间内频繁访问的数据,Windows-LRU 可以很好的适应这种访问模型
针对真正的热点数据,很快就会从 Window-LRU 进入到 Protected 区中,并且会经过保鲜机制存活下来。
8.为什么要用LSMTree,有什么针对性优化
LSMTree是非就地更新的数据结构,有高性能的顺序写。由于kv在设计之初就是在key后append一个时间戳(表示版本)。为了发挥顺序写的高性能特性,在更新key时是直接写入文件,而不是去覆盖历史版本因此,对于同一个 key 的多次更新会导致其不同版本分散在多个 SST 文件中。读取时系统需要遍历这些文件来确定最新版本的数据,增加了读取路径上的 I/O 操作次数,从而降低了读取性能。这就是读放大
LSM 的c0层是内存dump下来的全量数据,c0层是无序的 。c1-ck是文件并归排序和并后的有序文件。由于ci+1 是ci中具有重叠部分的文件合并的产物,因此可以说在同一层内是不存在重叠key的。在文件合并的过程中,不同层是有相同数据的,为了合并不同层级的 SST 文件,旧的数据会被重新读取、排序并写回到磁盘,这使得每次 compaction 都会产生额外的写入操作。这就是写放大。写放大会增加磁盘 I/O 负载,影响系统的整体写入性能。
9.如何设计一个高效的压缩算法,优化读写放大问题
遇到的问题:1.实现一种Lx到Ly压缩(归并排序)sst的分层机制,提高查询效率。2.正确的识别无效的key(不会再被访问的key)并将其删除,提高空间利用率。
原LSM的暴力解:
1.针对L0层的sst全部是从内存表dump没有经过合并因此必然存在重叠区间的事实,每次L0层文件数量或者所有sst文件的总字节数达到一个阈值的时候就会触发合并,将L0层中相互重叠的sst文件选中(可能有多个重叠组),然后将L0的重叠组和L1中的所有文件进行比较,将L1中与重叠组有重合的sst加入重叠组,判断重叠只需要比较sst的最大key和最小key即可(sst文件本身是有序的),而二者都已经在table的索引元数据中被记录,因此是没有性能损失的。
2.对于L1到L6的其他合并,只需要在当前level的size超过阈值后选择其中fid最小的那个sst文件(最旧的),和下一层的所有sst文件判断是否有重叠后选中有重叠的sst文件然后执行多路归并生成新的sst文件。
3.在合并的过程中需要不停的合并同一个key的不同版本,所以必须要对至少两个sst文件施行归并排序,由于每个sst文件本身都是有序的,不同key按升序排序,相同的key按版本的降序排序,因此合并时仅写入第一个key,而忽略相同key的其他版本即可实现压缩。
corekv的优化:
- L0层因sst是无序的,合并时会涉及较多的sst,如何优化读写延迟?
⛱️合并时,对涉及的sst加读锁,保证依旧可以对外检索,而minor的过程只会向L0添加新sst,因此可以保证是无阻塞的,同时当major compact结束后才会删除sst文件,此步骤会造成阻塞(可通过mv的方式原子删除提高并发度)。对L0层的查询最坏情况可能要遍历所有的sst文件,因此对L0层sst文件自身进行压缩,可以有效减少L0层sst文件的数量,进而提高查询性能。
- compact过程需要从Ln到Ln+1,一个有效key至少经历7次的移动,写放大严重如何解决?
⛱️如果Lmax层没有达到预期的容量,可以直接实现L0到Lmax的压缩,进行跨层级压缩,来减少写放大的可能性。
- l6层的数据会越来越多,是否会导致数据倾斜?过期的key在l6层如何被清理?
⛱️数据到达L6层后将无法被压缩到下一层,因此实现L6层自身的压缩,可以清理L6层的无效数据,提高空间利用率和性能。
- 为充分发挥ssd的并行度,如何实现并行compact压缩,来提高性能?
⛱️level级别和table级别都加上读写互斥锁,然后维护一个全局的关于sst的状态表,记录每一个压缩任务的执行状态以及涉及的sst有哪些,在生成压缩计划的时候,检查其互斥性,如果当前压缩任务涉及的sst文件与正在执行的其他压缩任务没有冲突则可以执行否则失败。
- 对于Lx到Ly的压缩,如果选择x与y 才能使得整体压缩效益最大化,节省空间提高性能?
⛱️L0层根据sst文件的数量来决定,其他层根据每个level的去除正在压缩状态的sst文件的总size与每层的期望size的比值作为优先级,而每个level的期望size之间相差一个数量级。
- 压缩过程执行到一半,数据库崩溃后数据的一致性如何保证?
⛱️只有在manifest文件状态变更成功后,才会向Lx中删除老旧的sst,并在Ly中添加新的sst文件。
- 多个协程执行并行压缩,如果频繁出现并发冲突该如何解决?
⛱️在多个并发执行的压缩器初始化时,给予一个500ms左右的随机时间,使得每个压缩器执行的并发性被打散,降低冲突的可能性。
- 压缩时读取sst文件到内存进行排序是否会造成OOM?
⛱️使用迭代器模式,从磁盘中逐条拉取数据到本地,减少内存的使用避免OOM,并且可以适当的使用并行预取机制,优化读取性能。
- 迭代器的range是否会破坏block的缓存?
10.实现事务时要如何考量
在CoreKV中,已经天然支持了多版本的数据结构。每一个Key在写入的时候,都会携带一个时间
戳。
内存部分
corekv的整体设计是仿照leveldb,是一个内存+磁盘的数据库。大概的设计思路是:
在内存中缓存最新的写入数据,当内存中的数据块达到一定大小时,会被转换为不可变的SST
0.与其他数据库比较
1.redis
redis是纯内存数据库,支持的数据类型有:
char *strEncoding(int encoding) {
switch(encoding) {
case OBJ_ENCODING_RAW: return "raw";
case OBJ_ENCODING_INT: return "int";
case OBJ_ENCODING_HT: return "hashtable"; //dict
case OBJ_ENCODING_QUICKLIST: return "quicklist";
case OBJ_ENCODING_ZIPLIST: return "ziplist";
case OBJ_ENCODING_INTSET: return "intset";
case OBJ_ENCODING_SKIPLIST: return "skiplist";
case OBJ_ENCODING_EMBSTR: return "embstr";
default: return "unknown";
}
}
//由上可见字符串分为”raw”和”embstr”,其实还有一种就是int.redis中的对象有:
| 数据类型 | 适用场景 | 备注 |
|---|---|---|
| 字符串(string:包括”raw”和”embstr”和“int”) | 缓存功能:mysql存储,redis做缓存 计数器:如点赞次数,视频播放次数 限流:见基于redis的分布式限流 | 简单型的。如set stunum studentInfo。 计数器如限流 |
| 列表(list:即"quicklist") | lpush+lpop=Stack(栈); lpush+rpop=Queue(队列); lpush+ltrim=Capped Collection(有限集合); lpush+brpop=Message Queue(消息队列); 文章列表: 可以使用组合的方式文章用hash存储,而文章列表则使用list存储 | 如阻塞队列,关注列表 |
| 哈希(hash:包括“ziplist”和“dict”) | 对象属性(尤其不定长的) | 如缓存studentInfo,hmset stunum stunum 1 stuname dinghaha age 18 |
| 集合(set:包括“intset”和“dict”) | 可以使用组合的方式文章用hash存储,而文章列表则使用list存储 适用社交场景 | 赞/踩、粉丝、共同好友/喜好、推送 |
| 有序集合(zset:包括“ziplist”和“dict+skiplist”) | 排行榜(主要是视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播放数量、按照获得的赞数);优先队列;缓存相关的元数据(比如按照排序的挑战) |
上面的所有对象都基于 redisObject这个基础对象:
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4; //4种对象类型
unsigned encoding:4; //该对象底层数据结构对应的编码方式
unsigned lru:LRU_BITS; //使用内存淘汰算法进行内存回收时的标记
int refcount; //对应于object refcount命令
void *ptr; //模拟多态,可以存储任何类型的对象。
} robj;可以看出,在这个基类里就做好了每个对象的内存管理(即分配和回收)
2.与leveldb的区别
corekv和leveldb一样,都引入了内存池Area.leveldb是c++写的,有很多自定义的内存申请,优化和回收策略。而corekv引入Area的策略是:就是首先使用预分配一块比较大的内存,需要使用小块内存时,从这块大内存里面继续分配,这时候分配可能只是移动指针或者更新变量,非常高效。使用这种思想,解决了小块内存频繁调用的开销和内存碎片的问题,但是却可能浪费一些内存,但由于设计架构,arena会持久化为sst,然后被释放,并不会被真正浪费。
1 内存池arena
1.1 arena内存管理的思路
我们的Arena只提供分配空间的操作,不提供释放空间的操作。这是因为在CoreKV的应用场景中,所有的操作都被当做在Arena内存池中的追加操作,当Arena在内存中占用的空间超过一定阈值以后CoreKV:会将整个memtable转变为immutable,随后会持久化成sst文件。那时,整个Arena内存空间可以被释放。所以,Arena内存空间的释放不需要自己完成,借助Golang语言的内存回收机制即可。
就是首先使用预分配一块比较大的内存,需要使用小块内存时,从这块大内存里面继续分配。体现在数据结构上就是:
只需要知道当前所用的内存块在大内存中的偏移量(即起始地址)和内存块的长度,即可在这块大内存中访问到当前内存块
arena结构体:
// Arena 是一个无锁的内存管理结构,用于高效地管理和分配内存。
// 它通过避免使用锁机制来提高并发性能。
type Arena struct {
// n 用于记录当前Arena中已分配的字节数。
n uint32
// shouldGrow 标志指示是否应该在分配新对象时增加缓冲区大小。
shouldGrow bool
// buf 是一个字节数组,用于存储分配的内存对象。
buf []byte
}不论是什么类型的键或值,在内存池中,都是以字节的形式存储,这就涉及到一系列编解码的方法
Arena 本身不负责并发安全。
1.2 arena 接口
以下是Arena结构体的主要接口:
newArena(n int64) *Arena: 创建一个新的Arena实例,用于管理缓冲区。参数n指定缓冲区的初始大小。allocate(sz uint32) uint32: 从Arena的缓冲区中分配指定大小的内存空间。它会更新已分配的内存偏移量,并在必要时扩容缓冲区。返回分配的内存空间的起始偏移量。func (s *Arena) allocate(sz uint32) uint32 { // 相当于线程安全的:offset = s.n+sz offset := atomic.AddUint32(&s.n, sz) // 如果不应扩容,那么检查偏移量是否超出当前缓冲区的范围。 if !s.shouldGrow { AssertTrue(int(offset) <= len(s.buf)) return offset - sz } if int(offset) > len(s.buf)-MaxNodeSize { //初始化扩容大小 growBy 为当前缓冲区的长度。 growBy := uint32(len(s.buf)) //检查扩容大小是否超过了 1GB (1<<30 字节)。 if growBy > 1<<30 { growBy = 1 << 30 } if growBy < sz { growBy = sz } //即 sz<=growBy<=1GB // 扩容缓冲区,+int(growBy)是为了避免 checkptr 错误,我们需要在缓冲区末尾保留额外的字节。 newBuf := make([]byte, len(s.buf)+int(growBy)) AssertTrue(len(s.buf) == copy(newBuf, s.buf)) s.buf = newBuf } return offset - sz }size() int64: 返回当前Arena中已分配的字节数。putNode(height int) uint32: 在Arena中分配一个跳表的节点。节点将在指针大小的边界上对齐。返回节点的 arena 偏移量。getNode(offset uint32) *node: 返回位于offset处的跳表节点的指针。如果偏移量为零,则返回空指针。putVal(v ValueStruct) uint32: 将ValueStruct类型的值v放入Arena。返回值的 arena 偏移量。getVal(offset uint32, size uint32) (ret ValueStruct): 返回offset处的值。putKey(key []byte) uint32: 将键key放入Arena。返回键的 arena 偏移量。getKey(offset uint32, size uint16) []byte: 返回offset处的键。getNodeOffset(nd *node) uint32: 返回跳表节点的 arena 偏移量。如果节点指针为空,则返回零偏移量。
这些接口实现了无锁的内存管理,提高了并发性能。在分配内存和扩容缓冲区时,都是通过原子操作实现的,不需要使用锁。这样可以确保在分配内存时的线程安全。
1.3arena中的内存对齐
为啥要内存对齐
首先我们需要知道内存对齐的粒度,也就是操作一个内存单元的粒度。计算机系统中对齐的粒度一定都是2的n次方(计算机组成原理决定的,不懂的去学一下,这里不深入了),这个数用二进制表示一定是1000...000(是2的几次方,就是1后面跟几个0)
注意:我们这里的内存单元不一定是物理意义上内存单元,取决于你的代码。如果你的代码申请和读取内存都是按8Bytes为单位进行的,那你的内存对齐可能就需要用8Bytes来处理。
内存对齐的意思,粗略的讲就是处理成内存单元的整数倍,例如大小为6字节的数据,要给他分配8字节的空间,一个14字节的数据,要给他分配2个8字节。这样就避免了一些性能浪费,6字节的数据本来可以一次读取,如果不进行内存对齐,可能会造成横跨了两个内存单元,要读取两次内存。
举个例子
|---6Bytes---|---6Bytes---|
|----8Bytes----|----8Bytes----|
在读取第二个6Bytes的时候,要读取两个8Bytes的内存单位,才能将第二个6Bytes的数据完全读起来。因为他在两个内存单元里都留了一部分数据。
|---6Bytes-----|---6Bytes-----|
|----8Bytes----|----8Bytes----|
如果做了对齐,也就是每个6Bytes放在一个8Bytes的内存单位内,读取第二个6Bytes,只需要一次读取,将第二个8Bytes读取就可以。
内存对齐的方法
步骤一:按内存单元取整数倍
刚才提到的问题,解决办法是内存对齐要做的第一件事:按内存单元的粒度取整数倍,这样才能保证让数据不要横跨内存单元。
当然有些情况是不可避免的,比如14Bytes,是必须要跨两个内存单元。
用位运算去做这个事情就是 size & ~(ALIGNMENT - 1),下面我们详细解释一下
内存单元的大小用二进制表示一定是100...000(刚才说过了),减1以后就是00...001111(后面的0全变成1),这个我们称为对齐掩码 mask
再对mask取个反,就变成前面全是1,后面跟着n个0,11111...110000,
最后用size & ~mask,得到的就是size按内存单元取整的结果,因为最后面的n个位被&运算处理成了0。
步骤二:向上取整
经过上面的步骤完成了按倍数计算,但是出现一个新问题,如果要分配的size还没有一个内存单元大,那么按倍数取整以后就会是0,这个显然是不对的,我们总不能给要写入的数据分配0个字节。
那么怎么解决这个问题呢?我们想给要写入的数据加上一个内存单元不就好了嘛,6Bytes的数据,我们加上一个8Bytes,这样再去求整数倍,肯定能保证分配一个内存单元。(这个我们称为向上取整,就是为了保障最小的分配空间)
不错,这样处理是对的,但是有个corner case,如果要申请数据空间就是8Bytes,再加8Bytes,这样就会申请16Bytes,也就是2个内存单位,其实刚好1个内存单元就可以刚好存下。咋办呢?
答案是, 用size + (mask)去申请,mask是谁?内存单元大小 - 1。size + 内存单元大小 - 1 = size - 1 + 内存单元大小,如果size - 1不够一个内存单元,就只需要分配一个内存单元。如果size - 1等于内存单元大小,意味着不得不分配两个内存单元。
举个栗子
假设对齐的粒度是8字节,我们记为 MEM_ALIGNMENT ,这个常量是000...1000(最后三个0)
MEM_ALIGNMENT-1,就是00...000111(最后三个1)
再进行位反运算,那就是11...111000(最后三个0),一个数&上这个数,最后3位一定为0,意思也就是按8字节取整
((size) + MEM_ALIGNMENT - 1) & ~(MEM_ALIGNMENT-1))
我们记 (size) & ~(MEM_ALIGNMENT-1) 为向下取整;((size) + MEM_ALIGNMENT - 1) & ~(MEM_ALIGNMENT-1)) 为向上取整
以接口putNode(height int) uint32为例:
// putNode 在Arena中放置一个节点,并返回该节点的对齐偏移量。
// height 参数指定节点的高度,用于计算未使用的大小。
const nodeAlign = int(unsafe.Sizeof(uint64(0))) - 1
func (s *Arena) putNode(height int) uint32 {
// 计算由于高度小于maxHeight而永远无法使用的塔的部分大小。
unusedSize := (maxHeight - height) * offsetSize
// 为分配加上足够的字节,以确保指针对齐。
l := uint32(MaxNodeSize - unusedSize + nodeAlign)
n := s.allocate(l)
// 返回对齐后的偏移量。
m := (n + uint32(nodeAlign)) & ^uint32(nodeAlign)
return m
}注意:在c++,java,python,js中,用~a表示a取反,而在go语言中,用^a表示a取反。在所有语言中,异或运算都用a^b表示
2.内存数据结构:支持Arena的无锁SkipList
SkipList和arena一样,本身不负责并发安全,它的并发安全性取决于 LevelDB 的整体设计和实现。
2.1 SkipList数据结构:
type SkipList struct {
arena *Arena // arena 指向存储节点数据的内存空间,类似于内存池。
headOffset uint32 // headOffset 是头节点在 arena 内存空间中的偏移量,用于快速访问头节点。
height int32 // height 表示当前跳表的高度,决定了最高节点中的指针数量。
ref int32 // ref 计数跳表的引用次数,用于引用计数垃圾回收机制,引用计数是一种内存管理方式。在leveldb中,memtable/version等组件,可能被多个线程共享,因此不能直接删除,需要等到没有线程占用时,才能删除。
Onclose func() // Onclose 是一个回调函数,在跳表关闭或销毁时调用,用于执行清理操作。
}跳表节点数据结构:
/**
1.Node中的value不再是具体的值,而是可以描述在Arena当中的位置的变量。描述在Arena中
位置,需要得知在Arena当中的offset和length,这里将两个值按固定长度编码在一起,用一个
uint64类型的变量来表示,方便使用CAS机制来修改、读取value.
2.Node中的Key同样不是存储具体的值,但是这里没有将key合并编码,这是因为key值本来就
是不可以被更新的,也就不存在并发操作,没必要合并编码。
*/
type node struct {
// value 字段用于存储节点的值。它被编码为 uint64 类型,以便可以原子化加载和存储。
// 具体编码方式为:值偏移量使用 UInt32 表示(位 0-31),值大小使用 UInt16 表示(位 32-63)。
value uint64
// keyOffset 表示节点键在存储介质中的偏移量。
keyOffset uint32
// keySize 表示节点键的大小。
keySize uint16
// height 表示节点位于哪一层。
height uint16
// levels 数组用于存储指向其他节点的指针,最大高度为 maxHeight。
// 这个设计使得节点能够快速访问其子节点,从而提高树操作的效率。
levels [maxHeight]uint32
}与v(value) 相关的数据结构
type ValueStruct struct {
Meta byte // 元数据字段,用途和具体含义根据实际业务逻辑定义。
ExpiresAt uint64 // 过期时间字段,使用Unix时间戳表示,用于确定值的过期时间。
Value []byte // 值数据字段,存储实际的值信息,类型为字节切片。
Version uint64 // 版本字段,用于内部跟踪值的版本变化,不会被序列化。
}value在内存中的真正存储形式就是ValueStruct编码后的字节数组
2.2 Redis中的线段跳表:
先看看传统的跳表(二分跳表,类似于Redis中的)
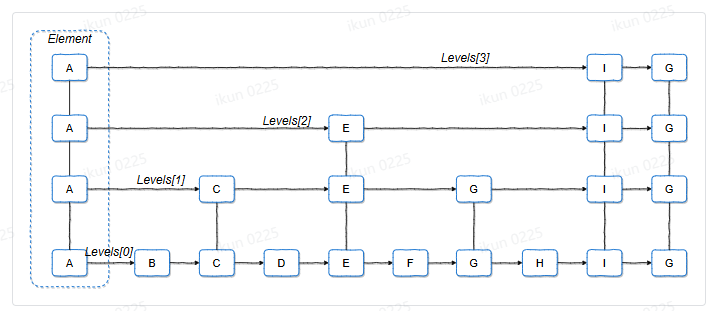
//可能一个节点会存在多层
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;//成员对象
double score;//各个节点中分值,在跳跃表中,节点按各自所保存的分值从小到大排列
struct zskiplistNode *backward;//指向位于当前节点的前一个节点。后退指针在程序从表尾想表头遍历时使用
struct zskiplistLevel {
struct zskiplistNode *forward;//用于访问位于表尾方向的其他节点,当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行
unsigned long span;//跨度,他和遍历操作无关,forward才是用来遍历操作的。跨度实际上是用来计算排位的。
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;//节点个数
int level;//总层数
} zskiplist;
2.3 redis线段跳表和kv中跳表的差别
1.线段跳表中levels[i]表示:该节点在第i层的下一个节点的指针(地址);在kv中表示:该节点在第i层的下一个节点在arena中的偏移量。
这里补充一个go语言的语法问题:go语言的指针和c++不同,有如下限制:1.指针不能参与运算。2.不同类型的指针不允许相互转换。3.不同类型的指针不能比较和相互赋值 。因此通过buf[offset] 并不能获得node指针,需要借助unsafe.Pointer转化
2.线段跳表节点中有backward指针,可以倒着遍历,kv中没有
3.线段跳表中的key只有存储作用(是其中的ele字段),排序(增、查)时用的是score字段;kv中所有的key都是string,而后被转化为字节数组,通过字节数组来排序(增、查)
2.4 SkipList主要接口
先看一下最简单跳表的接口:LeetCode 1206. 设计跳表
要提供的接口无非是:增、删、查;按照思路,要提供一个函数,可以找到小于key的最大值和大于key的最小值的函数(类似于二分法),然后将节点在这个位置插入或删除
增:
// Add 向跳表中添加一个条目。
// 如果键已存在,则更新对应的值而不增加跳表的高度。
// 这里的设计允许覆盖,因此我们可能不需要创建新节点或增加高度。
func (s *SkipList) Add(e *Entry) {
// 从条目中提取键和值信息
key, v := e.Key, ValueStruct{
Meta: e.Meta,
Value: e.Value,
ExpiresAt: e.ExpiresAt,
Version: e.Version,
}
// 获取当前跳表的高度
listHeight := s.getHeight()
// 初始化用于存储每一层节点偏移量的 prev 和 next 数组
var prev [maxHeight + 1]uint32
var next [maxHeight + 1]uint32
// 设置搜索起点为头节点的偏移量
prev[listHeight] = s.headOffset
// 从最高层开始向下搜索以找到插入点
for i := int(listHeight) - 1; i >= 0; i-- {
// 使用更高层级的信息来加速当前层级的搜索
prev[i], next[i] = s.findSpliceForLevel(key, prev[i+1], i)
if prev[i] == next[i] {
vo := s.arena.putVal(v)
encValue := encodeValueLocation(vo, v.EncodedSize())
prevNode := s.arena.getNode(prev[i])
prevNode.setValue(encValue)
return
}
}
// 我们确实需要创建一个新的节点
height := s.randomHeight()
x := newNode(s.arena, key, v, height)
// 尝试通过 CAS 更新 s.height
listHeight = s.getHeight()
for height > int(listHeight) {
if atomic.CompareAndSwapInt32(&s.height, listHeight, int32(height)) {
// 成功增加了跳表的高度
break
}
listHeight = s.getHeight()
}
// 总是从基础层级插入。在基础层级添加节点后,不能在上一层级创建节点,
// 因为它会发现基础层级的节点。
for i := 0; i < height; i++ {
for {
if s.arena.getNode(prev[i]) == nil {
AssertTrue(i > 1) // 在基础层级不可能发生这种情况
// 高度超过了旧的高度,因此我们没有计算这个层级的 prev 和 next。
// 对于这些层级,我们期望列表是稀疏的,所以我们可以直接从头部搜索。
prev[i], next[i] = s.findSpliceForLevel(key, s.headOffset, i)
// 有人在我们能够插入之前添加了完全相同的键。这只能发生在基础层级,但我们知道我们不在基础层级。
AssertTrue(prev[i] != next[i])
}
x.levels[i] = next[i]
pnode := s.arena.getNode(prev[i])
newNodeOffset := s.arena.getNodeOffset(x)
if pnode.casNextOffset(i, next[i], newNodeOffset) {
// 成功在 prev[i] 和 next[i] 之间插入 x。进入下一层。
break
}
// CAS 失败。我们需要重新计算 prev 和 next。
// 重做搜索时尝试使用不同的层级不太可能有帮助,
// 因为在 prev[i] 和 next[i] 之间插入大量节点的可能性不大。
prev[i], next[i] = s.findSpliceForLevel(key, prev[i], i)
if prev[i] == next[i] {
AssertTrueF(i == 0, "相等的情况仅在基础层级发生: %d", i)
vo := s.arena.putVal(v)
encValue := encodeValueLocation(vo, v.EncodedSize())
prevNode := s.arena.getNode(prev[i])
prevNode.setValue(encValue)
return
}
}
}
}// findNear 在跳表中查找最接近给定键的节点。
// key: 要查找的键。
// less: 如果为true,表示查找小于key的最大键;如果为false,表示查找大于key的最小键。
// allowEqual: 如果为true,当查找的键正好存在于跳表中时,允许返回该键。
// 返回最接近key的节点和一个布尔值,表示是否找到了相等的键。
func (s *SkipList) findNear(key []byte, less bool, allowEqual bool) (*node, bool) {
x := s.getHead() // 从跳表的头节点开始。
level := int(s.getHeight() - 1) // 从跳表的最高层开始查找。
var pre [maxHeight]*node // 用于存储每一层小于 key 的最大节点。
for i := level; i >= 0; i-- {
for next := s.getNext(x, i); next != nil && CompareKeys(key, next.key(s.arena)) > 0; next = s.getNext(x, i) {
x = next
}
pre[i] = x
}
// 从最底层开始处理
x = pre[0]
next := s.getNext(x, 0)
if next == nil {
return s.handleEndOfList(x, less)
}
cmp := CompareKeys(key, next.key(s.arena))
if cmp == 0 && allowEqual {
return next, true
}
if less {
return s.handleEndOfList(x, less)
}
return next, false
}
func (s *SkipList) handleEndOfList(x *node, less bool) (*node, bool) {
if less {
if x == s.getHead() {
return nil, false
}
return x, false
}
return nil, false
}在某一层上从前往后遍历,找到目标值的函数
// findSpliceForLevel 在指定层级上查找键 key 的前驱和后继节点偏移量。
// 参数 key 是要查找的键,before 是当前节点在节点池中的偏移量,level 是当前操作的层级。
// 返回值是前驱节点偏移量和后继节点偏移量。
func (s *SkipList) findSpliceForLevel(key []byte, before uint32, level int) (uint32, uint32) {
for {
// 提前假设 before 节点的键小于 key,这是基于二分查找的思想。
beforeNode := s.arena.getNode(before)
next := beforeNode.getNextOffset(level)
nextNode := s.arena.getNode(next)
// 如果下一个节点为空,则找到了正确的前驱和后继。
if nextNode == nil {
return before, next
}
// 获取下一个节点的键。
nextKey := nextNode.key(s.arena)
// 比较当前键和下一个节点的键。
cmp := CompareKeys(key, nextKey)
// 如果键相等,则找到了目标节点。
if cmp == 0 {
return next, next
}
// 如果当前键小于下一个节点的键,则找到了正确的前驱和后继。
if cmp < 0 {
return before, next
}
// 否则,继续在当前层级向右移动。
before = next
}
}注:无论是哪种跳表,在实际存储时并不像规整的多叉树,而是每个节点插入时都随机一个高度,表示它会存在前几层。它的期望概率是n分之一,所以查找效率概率上等于n叉树
2.5 跳表插入的真实案例
2.缓存cache
缓存系统采用多种缓存策略和技术来优化存储和检索效率。它结合了限长缓存(window LRU),分段 LRU(segmented LRU),布隆过滤器(Bloom Filter)
以及计数迷你缩略图(count-min sketch)等多种方法来管理缓存数据。
实现更高效的缓存 解读TinyLFU算法__bilibili
2.1缓存设计面临的问题
缓存结构的引入主要就是为了解决热点数据问题。用什么策略来判断热点数据,怎样才能尽量保存到真正的热点数据.
缓存系统考虑了两个方面。即 :
1.在一个大时间周期中的热点数据
2.在一小段时间内突发的热点数据
3.中段时间尺度下的热点数据。在一小段时间内突发的热点数据如何能竞争过一个大时间周期中的热点数据。或者说以小时间周期为尺度时,如何保留大样本下的热门数据(即缓存保鲜问题)
这里举一个具体的场景。在一个视频网站的排行榜中,有每日热点,根据用户的使用情况,每日的下班时间也就是7点左右以后。大规模的用户开始使用网站。此时有一个做的爆款的视频被很多人浏览,成为热点数据。但是在7点以后这一两个小时内此爆款的引用次数虽然很多(假设1小时获得了10万播放)但和日热门100万播放一起来。显然无法在讨论次数上竞争过。热门这一套数据。但周热门在这个时间段内只有较少的访问量。
先来介绍一下常见的缓存淘汰策略
2.2 LRU
LRU (Least Recently Used) 最近最少使用算法
LRU 算法的思想是如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。所以,当指定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。也就是淘汰数据的时候,只看数据在缓存里面待的时间长短这个维度。
我们来看个例子
按照LRU算法进行访问和数据淘汰,10次访问的结果如下图所示
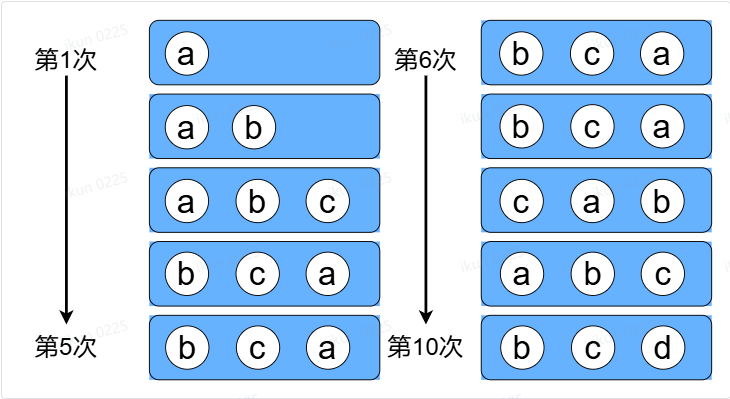
简单概括就是:以时间尺度为参考。淘汰掉老的数据
优点:在一个小的时间维度中,对于突发的高频率热点有一个很好的维护。
缺点:对于热点数据的命中率可能不如LFU
2.2 LFU
LFU(Least Frequently Used)算法在 LRU 的基础记录了每个 key 的访问频次。其依据访问频次来作为淘汰的依据,原理如下:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,将命中频次最少的数据淘汰。
简单概括就是:引入一个统计变量,统计出每个数据的访问频率。再根据频率淘汰数据。
优点:对于高频数据命中率更高
缺点:
1.曾经的高频数据始终占据缓存,即使已经很有没有访问该 key 的请求。
2.需要对每一个数据维护一个计数器,占用了大量的空间。
3.突发的稀疏流量由于频次较低,无法占据缓存。(导致短期内大量的数据库查询)
2.3 TinyLFU
TinyLRU 通过引入 Count-Min Sketch 算法来解决 LFU 面临的其中两个问题:
1.LFU 需要大量空间来统计频次信息(哈希计数)
2.LFU 存在高频旧数据长期不被淘汰(保鲜机制)
下面就来介绍一下 Count-Min Sketch 算法的核心原理。
在 LFU 中我们需要统计每一个 key 的访问频次,这时就需要使用一个整型或者长整型来存储这个计数。但是,我们真的需要这么大的空间来计数吗?在很多情况下,即使是热点数据也并不会被过多的访问,那么我们能否将进一步的压缩计数所占据的存储空间呢?
答案就是借鉴布隆过滤器中的思想位图。由于位图一个位的值只有 0 或 1 ,因此大部分情况下用其来做一些 bool 类型的状态标记(例如数据是否存在、用户是否登录等场景)。而如果我们将每个数据所占据的位数扩大,就可以标记更多的状态。
假设我们认为缓存中一个 key 被访问 15 次即作为高频数据,那么我们是不是能利用 4 个 bit 位来标记一项数据?这样就能够将原先的 32/64 bit 压缩至 4 bit,大大的减少了计数占据的空间。此时我们将一个 32 位的 int 划分为 8 个 4 bit 计数器,通过计算出数值对应的 int 下标以及其在 int 中偏移的位置,再加上位操作,就可以实现这样的计数。
下面的代码具体实现 Count-Min Sketch
type cmRow []byte
func newCmRow(numCounters int64) cmRow {
return make(cmRow, numCounters/2)
}
func (r cmRow) get(n uint64) byte {
return r[n/2] >> ((n & 1) * 4) & 0x0f
}
func (r cmRow) increment(n uint64) {
i := n / 2
s := (n & 1) * 4
v := (r[i] >> s) & 0x0f
if v < 15 {
r[i] += 1 << s
}
}
func (r cmRow) reset() {
for i := range r {
r[i] = (r[i] >> 1) & 0x77
}
}
func (r cmRow) clear() {
for i := range r {
r[i] = 0
}
}
// cmSketch 结构体代表一个计数明文布隆过滤器,用于快速判断一个元素是否在一个集合中。
// 它通过少量的哈希函数和位数组来实现高效的查询操作,尽管会存在一定的误判率。
type cmSketch struct {
// rows 数组存储了布隆过滤器的位数组行,每一行都是一个 cmRow 结构体,包含了一行的位信息。
rows [cmDepth]cmRow
// seed 数组存储了用于哈希计算的种子,每个种子对应一个哈希函数,用于确定元素在位数组中的位置。
seed [cmDepth]uint64
// mask 用于在哈希计算时快速定位到位数组的有效范围,通常是一个位掩码,确保哈希值落在正确的区间内。
mask uint64
}
// newCmSketch 函数用于创建一个新的 Count-Min Sketch 数据结构实例。
// 参数 numCounters 指定了计数器的数量。 该函数会检查 numCounters 是否为零,如果是则抛出异常。
// 然后,它会确保 numCounters 是2的幂,并初始化 cmSketch 结构体的各个字段,包括 mask、seed 和 rows。
// 参数 numCounters 指定计数器的总数,必须是一个正整数。 如果 numCounters 为 0,将触发 panic,因为这表示输入参数无效。
func newCmSketch(numCounters int64) *cmSketch {
if numCounters == 0 {
panic("cmSketch: invalid numCounters")
}
// 将 numCounters 调整为最接近的更大或相等的二次幂。
// 这是因为 Count-Min Sketch 的效率在计数器数量为二次幂时最佳。
numCounters = next2Power(numCounters)
// 创建 cmSketch 实例。 mask 用于高效计算哈希函数的索引,通过对 numCounters 减 1 得到。
sketch := &cmSketch{mask: uint64(numCounters - 1)}
// 初始化一个随机数源,用于哈希函数的种子。
source := rand.New(rand.NewSource(time.Now().UnixNano()))
// 对于每一行,初始化一个随机数种子和一个计数器数组。
// 这里的循环运行 cmDepth 次,是 Count-Min Sketch 的一个固定深度参数。
for i := 0; i < cmDepth; i++ {
// 为每一行生成一个随机数种子。
sketch.seed[i] = source.Uint64()
// 初始化该行的计数器数组。
sketch.rows[i] = newCmRow(numCounters)
}
// 最后,返回初始化完成的 cmSketch 实例。
return sketch
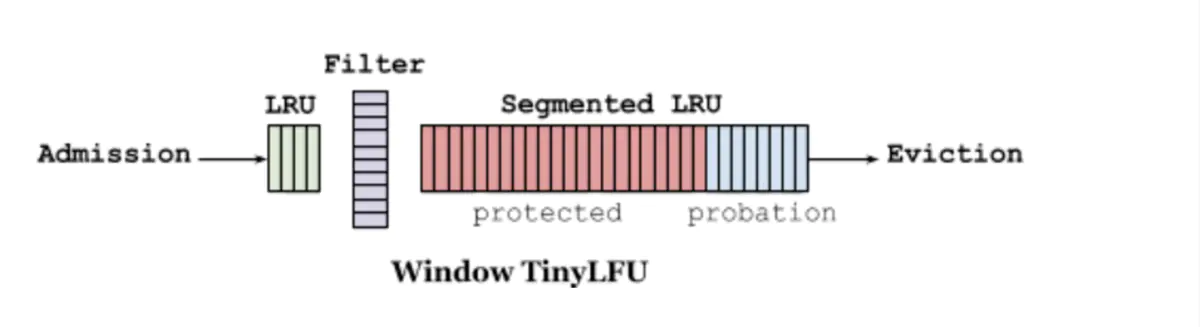
}2.4 KV采用的复合淘汰算法 Window-TinyLFU
知道了以上三种淘汰策略后,我们来构思kv的缓存设计思路:
我们希望结合LRU和TinyLFU,这样既可以很好的维护一个小的时间维度中,突发的高频率热点 又可以维护一段时间内突发的热点数据还要做到缓存保鲜
2.5Cache的数据结构
type Cache struct {
// m 用于同步访问缓存数据,确保并发安全。
m sync.RWMutex
// lru 作为短时高频数据的缓存策略,windowLRU 是一种基于滑动窗口的 LRU 缓存策略。
lru *windowLRU
// slru 用于存储较长时间未被访问的数据,segmentedLRU 是一种分段的 LRU 缓存策略,
// 它可以更有效地管理大量缓存数据。
slru *segmentedLRU
// door 用作快速判断某数据是否存在,使用布隆过滤器可以快速判断某数据是否存在缓存中,
// 但可能会有误判。
door *BloomFilter
// c 用于估计大量数据的频次,count-min sketch 是一种概率数据结构,用于估计数据流中
// 各项的频次。
c *cmSketch
// t 用于调整缓存策略的灵敏度,是一个动态调整的阈值。
t int32
// threshold 用于区分数据是否应该从 lru 晋级到 slru,确保高频数据能够被快速访问。
threshold int32
// data 用于存储具体的缓存数据,键是数据的唯一标识,值是双向链表的元素,
// 这样可以在 O(1) 的时间复杂度内访问和移除数据。
data map[uint64]*list.Element
}2.6数据在缓存中的流动过程
缓存分为2个大部分windowLRU(较小1%,时间尺度淘汰),segmentedLRU(较大99%)。segment-lru 又分为两个部分,一个占据20%叫做 Probation(缓刑),一个占据80%(Protected)。
当有数据进入缓存时,都先放到 window lru 中,如果window lru未满,直接插入到链表头部。如果window lru已满,需要根据 LRU 策略进行替换 获取链表尾部的项,这是最近最少使用的项。若LFU未满window lru 中淘汰的项会进入LFU。若LFU满则同时segment-lru的20% Probation(缓刑)区中会淘汰出末尾的项,它和window lru链表尾部的出来的项进行PK(这里进行 PK,必须在 bloomfilter 中出现过一次,才允许 PK,说明访问频率 >= 2)这两个数据中访问频率高的留下,留下的进入segmentedLRU的80%(Protected)。
在从缓存中拿数据时,要进行访问计数,计数过大时会在位图中把计数减半(保鲜机制),如此全局访问次数高但近期不太热门的数据就会被保留
布隆过滤器
1 布隆过滤器的作用
快速大致判断某元素是否在一个集合内
例如:
- 黑名单校验
- 快速去重
- 爬虫URL校验
- leveldb/rocksdb快速判断数据是否已经block中,避免频繁访问磁盘
- 解决缓存穿透问题
等等
在本kv项目中的应用点为:
2.布隆过滤器的构成与原理
数组的每个元素都只占1bit空间,并且每个元素只能为0或1。
布隆过滤器还拥有k个哈希函数,当一个元素加入布隆过滤器时,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在维数组中把对应下标的值置位1。
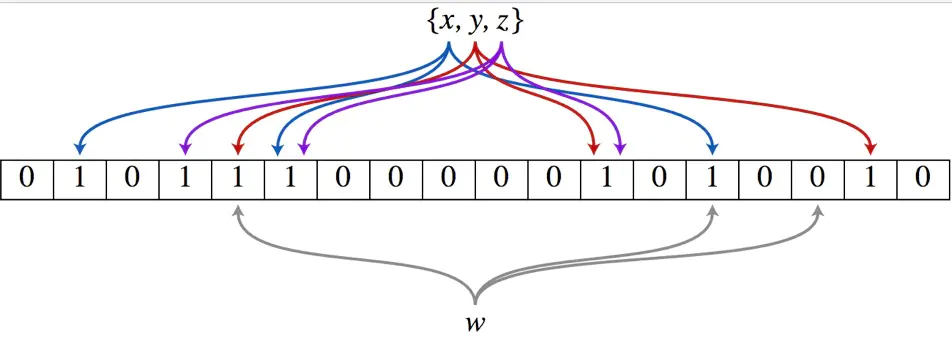
判断某个数是否在布隆过滤器中,就对该元素进行k次哈希计算,得到的值在位数组中判断每个元素是否都为1,如果每个元素都为1,就说明这个值在布隆过滤器中。
3.布隆过滤器的工作过程
- 初始化

- 插入geeks单词
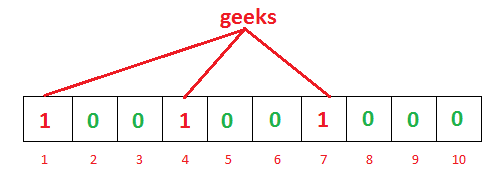
- 插入nerd
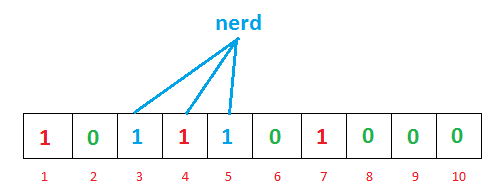
- 查询cat
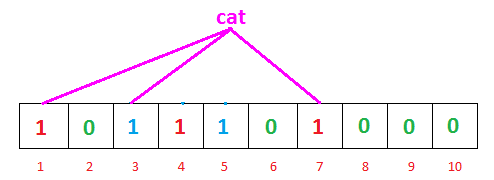
cat这个单词并不存在,但是此时1,3,7号位均为1,表示查询到了cat这个单词。此时需要去后台数查询。这个情况就是出现了误差。
布隆过滤器的误差率是指由于hash冲突,导致原本不再布隆过滤器中的数据,查询时显示在里面。
4.布隆过滤器的长度、哈希函数个数、与误报率
假设 Hash 函数以等概率条件选择并设置 Bit数组中的某一位,m 是该位数组的大小,k 是 Hash 函数的个数,n插入bit数组中的元素的个数,p为误报率。
我们知道,元素插入布隆过滤器要经过k次哈希计算,意味着有k个哈希函数。在数据库中,为了性能,我们希望减少计算次数,即减少哈希函数个数k。也希望省内存,即减小m。但从直观上看,这样做会使误报率变大,即查询精确度下降。我们希望去平衡性能(k),占用空间(m),和精确度(p)之间的关系。因此,引入数学证明,来求得一个相对最优解。
数学证明过程
数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位1的概率是:
那么在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:
如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:
因而该位为 "1"的概率是:
现在检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:
m 是该位数组的大小,n插入bit数组中的元素的个数。在实际应用中m和n都非常大(我们希望在任何情况下,确定一个k值,使误报率最小)。所以我们需要一个$m\rightarrow+\infty $ 时 k 的函数(n视为一个常数)
以下为推导过程:
${\because 当x\rightarrow0,(1+x)^{\frac{1}{x}}\rightarrow e} $ ①
又有 ②
$\because m\rightarrow+\infty $
此时可以将当成公式①中的X,那么原公式可推导出
不难看出,随着 m (位数组大小)的增加,假阳性(False Positives)的概率会下降,同时随着插入元素个数 n 的增加,False Positives的概率又会上升。
对于给定的m,n,如何选择Hash函数个数 k ?
根据我们推导出的误判率函数 。我们希望误判率最小,问题变为求 的最小值
以下为推导过程:
设:,则函数变为
两边取对数:
下面求最值:
结论
则误判率最低时,得出k值:
把k代入误判率公式,得出:
而对于给定的False Positives概率 p,如何选择最优的位数组大小 m 呢?
把k代入误判率公式,得出m值:
5.布隆过滤器实战
布隆过滤器数据结构
// Filter is an encoded set of []byte keys.
type Filter []byte
type BloomFilter struct {
bitmap Filter
k uint8
}先结合公式实现数学部分,求 。然后再向上取整以确保有足够的位数,最后再 得到。以下函数中numEntries 就是公式中的n,fp就是公式中的p
// BloomBitsPerKey 计算布隆过滤器每个关键字所需的位数。
// 该函数基于给定的关键字数量和期望的误报率来计算。
// 参数:
//
// numEntries - 布隆过滤器中预计要插入的关键字数量。
// fp - 期望的误报率,表示为浮点数(例如,0.01表示1%的误报率)。
// 返回值:
// 返回每个关键字推荐的位数,以整数形式表示。
func bloomBitsPerKey(numEntries int, fp float64) int {
// 计算Bloom过滤器大小(位数)所需的哈希函数数量。
// 使用自然对数来估算误报率的公式。
size := -1 * float64(numEntries) * math.Log(fp) / math.Pow(float64(0.69314718056), 2)
// 计算每个键所需的位数,向上取整以确保有足够的位数。
locs := math.Ceil(size / float64(numEntries))
return int(locs)
}创建布隆过滤器
// initFilter 初始化一个BloomFilter实例。
// 参数 numEntries 表示预计添加到过滤器的元素数量。
// 参数 bitsPerKey 用于估算过滤器中每个元素占用的位数。
// 返回值为一个指向初始化后的BloomFilter的指针。
func initFilter(numEntries int, bitsPerKey int) *BloomFilter {
// 创建一个BloomFilter实例
bf := &BloomFilter{}
// 确保bitsPerKey不为负值,负值在此上下文中无意义
if bitsPerKey < 0 {
bitsPerKey = 0
}
// 计算哈希函数的数量,0.69是大约ln(2)
k := uint32(float64(bitsPerKey) * 0.69)
// 确保哈希函数数量至少为1
if k < 1 {
k = 1
}
// 将哈希函数数量限制在30以内,以避免过多哈希函数造成的效率降低
if k > BloomFilterMaxHashes {
k = BloomFilterMaxHashes
}
// 设置BloomFilter的哈希函数数量
bf.k = uint8(k)
// 计算BloomFilter应包含的总位数
nBits := numEntries * int(bitsPerKey)
// 对于较小的元素数量,可能会看到很高的假阳性率。通过强制实行最小BloomFilter长度来修正
if nBits < 64 {
nBits = 64
}
// 在Bytes级别上的向上取整
nBytes := (nBits + 7) / 8
nBits = nBytes * 8
// 初始化过滤器字节数组
filter := make([]byte, nBytes+1)
// 在字节数组的末尾记录BloomFilter的哈希函数数量
filter[nBytes] = uint8(k)
// 设置BloomFilter的位图
bf.bitmap = filter
// 返回初始化后的BloomFilter实例
return bf
}再来看布隆过滤器工作过程的实现
// Allow 方法用于判断给定的元素是否已经被布隆过滤器接受。
// 如果元素已经被接受,则返回 true;否则,将其插入过滤器并返回 false。
// 这个方法首先检查自身是否为空,如果为空,则直接返回 true, 表示任何元素都可以通过空的布隆过滤器。
// 如果过滤器不为空且元素尚未被包含,则将其插入过滤器中。
// 如果元素已经被过滤器包含,则返回 true;否则返回 false。
func (f *BloomFilter) Allow(h uint32) bool {
// 检查布隆过滤器是否为空,如果为空,则任何元素都可以通过
if f == nil {
return true
}
// 检查元素是否已经存在于布隆过滤器中
already := f.MayContain(h)
// 如果元素不存在,则将其插入过滤器
if !already {
f.Insert(h)
}
// 返回元素是否已经存在的结果
return already
}
func (f *BloomFilter) reset() {
if f == nil {
return
}
for i := range f.bitmap {
f.bitmap[i] = 0
}
}
func (f *BloomFilter) reset() {
if f == nil {
return
}
for i := range f.bitmap {
f.bitmap[i] = 0
}
}6. 布隆过滤器减少哈希次数的优化
我们单独来聊插入操作
// Insert 将一个元素插入到布隆过滤器中。
// 该方法返回一个布尔值,表示插入是否成功。
// 参数:
//
// h - 要插入元素的哈希值。
//
// 返回值:
//
// 插入操作的结果,目前总是返回true。
func (f *BloomFilter) Insert(h uint32) bool {
k := f.k
// 当k大于30时,认为这是一个为短布隆过滤器可能的新编码保留的情况。
// 直接认为匹配成功。
if k > 30 {
return true
}
// 计算布隆过滤器比特数组的大小(比特数)。
nBits := uint32(8 * (f.Len() - 1))
// 计算一个用于后续哈希值变化的delta值。
delta := h>>17 | h<<15
// 对于每个哈希函数,计算比特位置并设置相应的比特为1。
for j := uint8(0); j < k; j++ {
// 计算当前哈希函数对应的比特位置。
bitPos := h % uint32(nBits)
// 设置比特位置为1。
f.bitmap[bitPos/8] |= 1 << (bitPos % 8)
// 更新哈希值以使用下一个哈希函数。
h += delta
}
// 插入操作成功。
return true
}
// Hash implements a hashing algorithm similar to the Murmur hash.
func Hash(b []byte) uint32 {
const (
seed = 0xbc9f1d34
m = 0xc6a4a793
)
h := uint32(seed) ^ uint32(len(b))*m
for ; len(b) >= 4; b = b[4:] {
h += uint32(b[0]) | uint32(b[1])<<8 | uint32(b[2])<<16 | uint32(b[3])<<24
h *= m
h ^= h >> 16
}
switch len(b) {
case 3:
h += uint32(b[2]) << 16
fallthrough
case 2:
h += uint32(b[1]) << 8
fallthrough
case 1:
h += uint32(b[0])
h *= m
h ^= h >> 24
}
return h
}这段代码参考的是leveldb的源码,仔细观察,它的实现方式和上面说的工作原理不同。上面论证了许多:要有k个哈希函数进行k次哈希。而此代码只用例一个哈希函数。这就涉及到源码中的一篇论文布隆过滤器优化算法double—hashing论文原文(一),下面总结论文的核心要点
6.1 论文要点总结
文献中提供了使用两个哈希函数 和 来模拟 形式的其他哈希函数的方法。也就是通过两个哈希函数进行k次运算,得到k个 新哈希函数 ,再做k次运算 达到k次哈希的效果。
论文用了柯西不等式,以及马尔可夫不等式来推导出
但是这依然和代码的实现方式不同,代码(leveldb)中,只用了一个哈希函数,用这一个哈希函数做了k次计算。这里来尝试论证这个理论的正确性。
首先采用的MurmurHash的哈希生成策略就是:循环处理输入字节数组中长度大于等于 4 的部分,将每 4 个字节转换为一个 32 位整数,并累加到哈希值 h 上。
对 h 进行乘法和位运算,以增加哈希值的随机性。而代码中也是把每次的哈希值h通过 生成一个新的整数 , 并累加到哈希值 h 上。这就等于一个全新的哈希值,且它没有用到seed 相当于一个更简单的哈希函数,这样就相当于满足了论文中的理论条件,且计算量更低,性能更高。
而且论文也论证了 和 ,所有的哈希值都是相同的情况下 ,以上结论仍然有普适性。也就是说,2个哈希冲突也不影响假阳性的收敛
磁盘部分
1. 磁盘上的存储结构
适合磁盘的索引结构通常有两种,一种是就地更新(B+Tree),一种是非就地更新(LSM)。
就地更新的索引结构拥有最好的读性能(随机读与顺序读),而随机写性能很差,无法满足现实工业中的工作负载要求。而非就地更新的索引结构-LSM充分发挥顺序写入的高性能特性,成为写入密集的数据系统的基础。
!!!注意。这里的性能指的不是读写的速度(延迟),而是读写的吞吐量(即读写数据的规模)。读写的延迟更多取决于物理设备,数据结构对其的影响并不大
磁盘上读写性能的影响因素是什么?
磁盘的物理结构和工作方式影响着读写性能。
磁盘是由盘片和磁头组成,数据存储在盘片上的磁信号中,读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右。
在固态硬盘中,数据存储在一个个电容中,电容通过加上不同的电压来存储数据,在ssd上找数据,不需要寻道和旋转,直接根据地址来寻址就好,所以速度比磁盘要快很多(最快的达到磁盘的几百倍),但是仍然远不如访问内存的成本。
所以,减少对硬盘的IO次数,是提高读写性能的最大因素
1.1 b+树的特点与优点
为什么b+树有良好的读性能?
针对减少对硬盘的IO次数 这一目标,b+树有着许多思路
1.尽量减少b+树的高度(层数)
索引是以页为单位的,B+树的一个节点就是一页(默认一页是16KB,这是多方验证得出的最优解);当数据量特别大的时候,每次只能把一页加载进内存,即使是SSD和内存的读写速度也差了10000倍,所以在内存中遍历的速度要远快于一次IO,所以,宁可让一个节点存很多数据,把数据放到内存中遍历(根据上一个问题的计算,最多在内存寻址1170次,也比1次IO快10倍),也要减少一次IO
2.所有数据都在叶子节点
在B+树中,所有的数据记录都存储在叶子节点上,而非叶子节点仅用于索引。这样做的好处是,一旦定位到了正确的叶子节点,就可以直接访问到所需的数据,而不需要进一步的查找。
3.磁盘友好的块大小
B+树设计时考虑到了磁盘的物理特性,每个节点的大小通常与磁盘块的大小相匹配,这样每次磁盘读写操作可以最大化地利用带宽,提高效率。
4.所有叶子节点链接,且都在同一层(最底层)
B+树的叶子节点之间通常是通过指针相互链接起来的,形成了一个链表。这种结构不仅支持随机访问,还支持范围查询和顺序扫描,因为可以通过叶子节点之间的链接快速地遍历相邻的记录。而且不论数据如何分布,B+树的性能都是比较稳定的,因为所有的数据都在同一层(即叶子层),这就避免了由于数据分布不均导致的性能波动问题。
1.2 LSM-Tree的特点与优点
1.将写入操作转化为顺序写入:
通过将写入操作转化为顺序写入,LSM-Tree减少了对磁盘的随机访问需求,这是提高写入性能的关键因素之一。
通过这些机制,LSM-Tree能够在写入大量数据时,通过减少磁盘的随机访问次数和充分利用顺序写入的优势来提高写入性能。当内存缓存达到一定大小时,数据会被批量写入到磁盘上的有序文件(如SSTable)。由于数据是在内存中排序后再写入磁盘,因此写入操作是顺序进行的,而顺序写入磁盘的速度远高于随机写入。然而,这种设计通常会在一定程度上牺牲读取性能,因此LSM-Tree更适合于写入操作频繁而读取操作相对较少的应用场景。
2.内存缓存(Memtable):
数据首先写入内存中的缓存结构(如Memtable)。这样可以利用内存的高速特性来加速写入操作,避免直接写入磁盘造成的性能瓶颈。
3.预写式日志(WAL):
为了保证数据的一致性和持久性,LSM-Tree通常还会维护一个预写式日志(Write-Ahead Log)。在数据写入内存缓存的同时,也会将变更记录到日志中。如果发生崩溃,可以通过日志恢复数据状态。
4.分层存储(Level-Based Storage):
磁盘上的数据被组织成分层结构,新数据先写入最顶层(如Level 0),随着时间推移,这些数据会被合并到下一层(如Level 1),以此类推。每一层的数据量通常比上一层大得多,这样可以减少合并操作的频率。
5.合并(Compaction):
随着时间的推移,同一键可能有多个版本存在于不同的层中。为了优化存储空间并减少读取时的开销,LSM-Tree会定期执行合并操作,将多个SSTable合并成一个新的、更大的SSTable。合并过程中会删除过时的键值对。
2.LSM-Tree介绍
参考博客:wiscKey论文精读 ,LSM树的数据存储技术解析
LSM树(Log-Structured Merge Tree)是一种用于高效存储和检索数据的数据结构。它通过一种特定的方式组织数据,以实现高吞吐量的写入操作和较快的读取性能。LSM树最初是为解决传统B树在写入操作上的性能瓶颈而设计的,特别适用于写入密集的场景,如分布式数据库、日志系统、缓存系统等。
LSM树的基本思想是将写入操作转化为顺序写的方式,这可以显著提高写入性能。它在内存中维护一个写入缓存,新的数据首先被写入该缓存,然后定期写入一个有序的日志文件。这些写入操作在内存中执行,从而避免了频繁的随机磁盘写入,提高了写入性能。随着时间的推移,内存中的数据会逐渐合并到磁盘上的多个层级,以维护数据的有序性和连续性。
LSM树在以下应用场景中非常有用:
- 分布式数据库:在分布式数据库系统中,LSM树可以处理大量的写入操作,这对于分布式环境下的数据一致性和可扩展性非常重要。LSM树的高写入性能和自动合并功能使得它成为许多分布式数据库引擎的核心技术。
- 日志系统:LSM树可以用于实现高性能的日志系统,例如分布式日志收集、审计日志等。它可以快速地处理大量的日志写入操作,并且保持日志数据的有序性,以便后续的查询和分析。
- 缓存系统:在缓存系统中,LSM树可以用于维护热数据,以实现高速的数据访问。由于LSM树的写入性能较高,缓存系统可以迅速地将热数据写入内存缓存,从而提供低延迟的访问。
- 大数据处理:对于需要高吞吐量和可扩展性的大数据处理任务,LSM树也可以作为数据存储引擎的选择之一,以处理大规模的数据写入和读取操作。
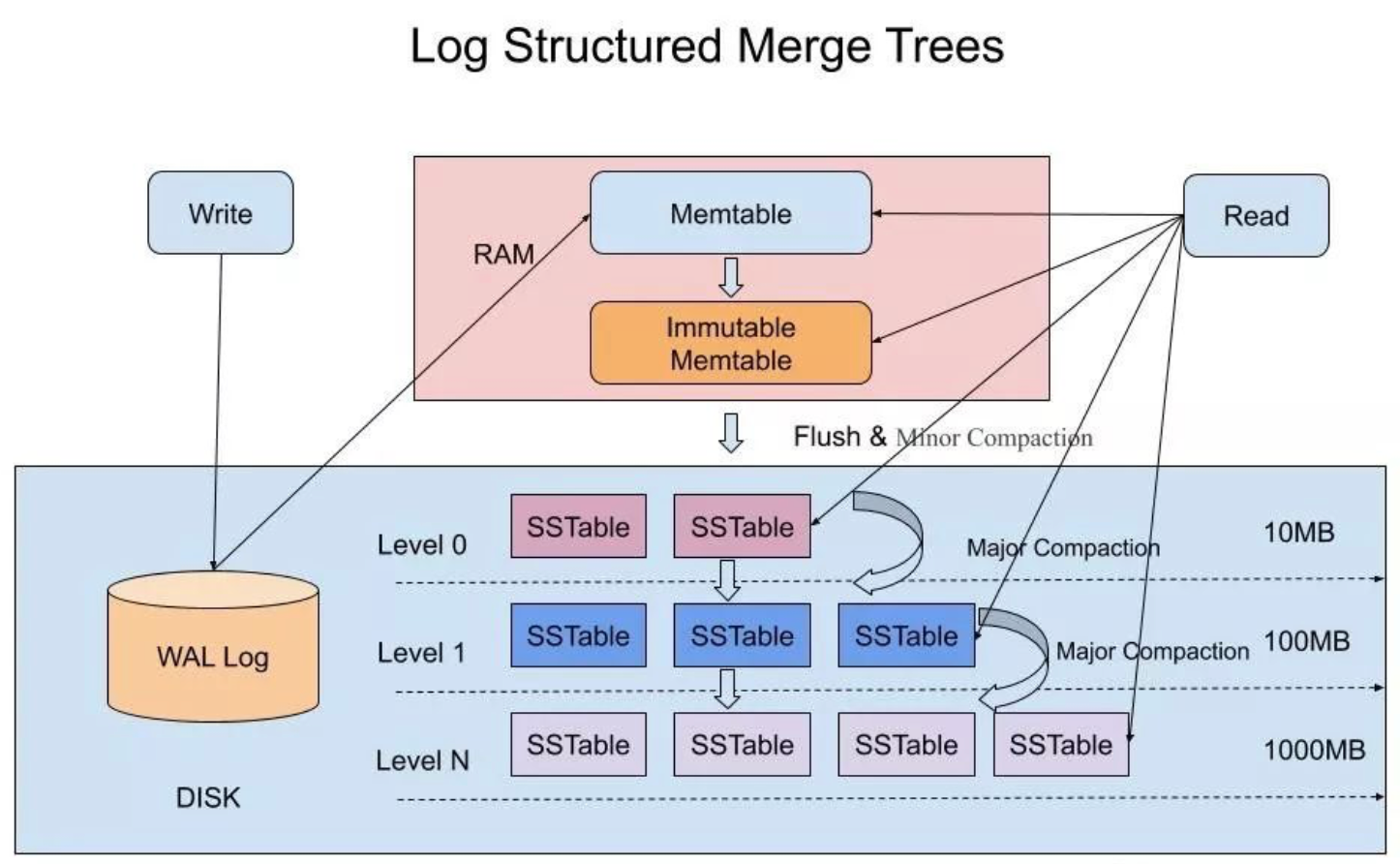
我们分别具体聊一下LSM-Tree的每一个特点的具体实现
2.1.将写入操作转化为顺序写入
顺序写入的写操作时间复杂度为O(1),但是带来的第一个问题就是:同一个key会占用多个存储空间(更新操作)。
直观的想法就是有一个无限大的文件可以无限追加数据。那么读取数据就需要从尾部一直读取到头部,找到的第一个key就返回,但是假设第一个key写入后从未更新那么想要读取此key每次就要读取全量的数据其读取复杂度为O(n),n为写入次数,同时范围查询就需要磁盘排序后输出O(NLogN)。
第一个优化想法就是合并这个无限大的文件,将被覆盖的key清理掉,只保留最新的key,但这样就不能在一个文件中操作(你不能边压缩边更新,类似GC),因此需要将文件分段。
文件会分段的另一个原因是,顺序写入也不满足性能要求,必须批处理,减少写吞吐,因此需要把数据暂存内存,到达一个阈值后flush整个数据到一个文件中。也就是特性2。
每次合并本质上是一次归并排序的过程(为了支持范围查询,以及空间压缩),那么就需要找到所有分段文件中有重合范围的文件,进行合并(min_key与max_key)。并且不能合并一个正在写入的文件(假设按大小划分文件)。
2.2.内存缓存(Memtable)
为了降低读取的复杂度,第一个想法就是利用内存,将最近最新写入的kv存储在内存数据结构中,红黑树,跳表等。
那么问题是何时将此数据结构dump到磁盘?最简单的是根据其大小的区别,然而在dump之前我们不能继续向其中写入数据。
因此在内存中应该存在一个活跃内存表和一个不变内存表,二者相互交替,周期性的将不变内存表dump到内存中形成一个分段文件。
2.3.预写式日志(WAL)
作为一个DB引擎,必须保证数据库进程崩溃前后的数据一致性,常见的做法就是使用预写日志。
将所有的操作记录在一个仅追加的log文件中(称之为WAL),所有的写入操作都要保证写入WAL成功后才能继续,因此当数据库崩溃后写入WAL的操作将被回溯,反之则被丢弃(只有写入WAL成功才会回复客户端ack)。那么从尾部重放这个WAL文件的操作即可恢复DB。
它跟事务有所不同,事务具有ACID的特性,且支持的范围具有普遍性。而LSM的“事务”只针对单一的键值对操作。LevelDB 保证了原子性,即单一键值对的put和delete等这些操作要么完全成功,要么完全失败。
2.4.分层存储与合并(Level-Based Storage)
在利用内存后,我们依旧没有解决最先写入且从未更新的key要读取全量数据的问题,
为解决这个问题LSM结构引入了分层设计的思想。
将所有的kv文件分为到共层。层是直接从不变的内存表中dump下的结果。而到是发生过合并的文件。
由于 是中具有重叠部分的文件合并的产物,因此可以说在同一层内是不存在重叠key的,因为重叠key已经在其上一层被合并了。那么只有层是可能存在重叠的文件的。
所以当要读取磁盘上的数据时,最坏情况下只需要读取的所有文件以及到每一层中的一个文件即c0+k个文件即可找到key的位置,分层合并思想使得非就地更新索引在常数次的IO中读取数据。
通常文件定义为2M,每一级比上一级大一个数量级的文件大小。所以高层(脚标大的层,也可以叫底层)的文件难以被一次性的加载到内存,因此需要一定的磁盘索引机制。
我们对每个磁盘文件进行布局设计,分为元数据块,索引块,数据块三大块。元数据块中存储布隆过滤器快速的判断这个文件中是否存在某个key,同时通过对排序索引(通常缓存在内存中)二分查找定位key所在磁盘的位置。进而加速读取的速度,我们叫这种数据文件为SSTABLE(字符串排序表)。
为了标记哪些SStable属于那一层因此要存在一个sstable的元数据管理文件,在levelDB中叫做MANIFEST文件。其中存储每一个sstable的文件名,所属的级别,最大与最小key的前缀。
2.5 LSM的组件
LSM(Log-Structured Merge-Tree)是一种数据结构,主要用于实现高效的写入和查询操作,常被应用在分布式存储系统和数据库引擎中。LSM树通常由以下组件构成:
- Write-Ahead Log (WAL):
- 在LSM树中,写入操作首先会被追加到Write-Ahead Log中,确保数据持久化到磁盘。WAL可以保证在系统故障时数据不会丢失。
- Memtable:
- Memtable是内存中的数据结构,用于暂时存储写入的数据。一般来说,数据先写入Memtable,当Memtable达到一定大小或者一定时间间隔后,会将数据按顺序写入到磁盘上的SSTable。
- Sorted String Table (SSTable):
- SSTable是LSM树中存储数据的磁盘文件格式,通常是已排序的键值对。在LSM树中会存在多个SSTable,每个SSTable都会包含一部分数据。
- Compaction:
- 为了减少读取时需要扫描多个SSTable的成本,LSM树会定期进行合并操作,将多个SSTable合并为一个更大的SSTable。这个过程叫做Compaction。
- Bloom Filter:
- Bloom Filter是一种数据结构,用于快速判断一个元素是否存在于一个集合中。在LSM树中,Bloom Filter可以减少不必要的磁盘读取,提高查询效率。
- Merge Policy:
- Merge Policy是决定何时进行Compaction操作的策略。不同的Merge Policy可以根据系统的负载情况和数据大小来决定何时进行合并操作。
这些组件共同作用,使得LSM树能够在写入大量数据时保持高效的性能,并且支持快速的查询操作。LSM树被许多开源数据库系统如LevelDB、RocksDB等所使用。
3.LSM-Tree实现思路(由顶层向下剖析)
先从接口开始分析(lsm/lsm.go)
LSM数据结构
// LSM 是一个结构体,代表一个日志结构合并树(Log-Structured Merge Tree)。
// 它主要用于数据库的底层存储引擎,以优化磁盘的读写效率。
// 该结构体包含了多个组件,每个组件在数据管理和检索过程中扮演着不同角色。
type LSM struct {
// lock 用于并发控制,确保对LSM树的读写操作是线程安全的。
lock sync.RWMutex
// memTable 是一个内存中的数据结构,用于存储新写入的数据,直到其大小达到一定阈值。
memTable *memTable
// immutables 是一个指向已变为不可变的memTable的指针切片,这些表已经满了,需要被刷新到磁盘。
immutables []*memTable
// levels 是一个层级管理器,控制着数据在多个层级的SSD表中的分布和合并。
levels *levelManager
// option 包含了LSM树操作的配置选项,如压缩、缓存等。
option *Options
// closer 用于通知LSM树停止操作,比如当一个数据库被关闭时。
closer *utils.Closer
// maxMemFID 是一个用于管理内存中数据块的标识的变量。
maxMemFID uint32
}因为LSM要向数据库(面向用户的DB层) 提供接口 ,所以要封装一个数据库运行所需的所有可调整选项
// Options 是一个配置结构体,包含了数据库运行所需的所有可调整选项。
type Options struct {
// WorkDir 指定了数据库文件存储的工作目录路径。
WorkDir string
// MemTableSize 设置了内存表(MemTable)的最大容量,单位为字节。
MemTableSize int64
// SSTableMaxSz 表示SSTable(磁盘存储数据表)的最大容量,单位为字节。
SSTableMaxSz int64
// BlockSize 定义了SSTable中每个数据块的大小,单位为字节。
BlockSize int
// BloomFalsePositive 设置布隆过滤器的误判概率。
BloomFalsePositive float64
// 以下为数据库压缩相关配置:
NumCompactors int // 压缩工作器的数量。
BaseLevelSize int64 // 基础层级的大小限制。
LevelSizeMultiplier int // 各层级之间的预期大小比例因子。
TableSizeMultiplier int // 表大小增长的乘数因子。
BaseTableSize int64 // 初始层级的基本表大小。
NumLevelZeroTables int // 层级0允许的最大表数量。
MaxLevelNum int // 数据库最大层级数。
// DiscardStatsCh 提供了一个通道,用于丢弃或统计特定操作的统计信息。
DiscardStatsCh *chan map[uint32]int64
}结合上文LSM组件,我们发现数据结构提供了所有组件需要的数据
创建
func NewLSM(opt *Options) *LSM {
lsm := &LSM{option: opt}
// 初始化levelManager
lsm.levels = lsm.initLevelManager(opt)
// 启动DB恢复过程加载wal,如果没有恢复内容则创建新的内存表
lsm.memTable, lsm.immutables = lsm.recovery()
// 初始化closer 用于资源回收的信号控制
lsm.closer = utils.NewCloser()
return lsm
}恢复wal的过程,
func (lsm *LSM) recovery() (*memTable, []*memTable) {
// 从工作目录中获取所有文件
files, err := ioutil.ReadDir(lsm.option.WorkDir)
if err != nil {
utils.Panic(err)
return nil, nil
}
var fids []uint64
maxFid := lsm.levels.maxFID
// 识别所有后缀为 .wal 的文件,并解析文件名中的 fid
for _, fileInfo := range files {
//检查文件名是否以特定扩展名 walFileExt 结尾
if !strings.HasSuffix(fileInfo.Name(), walFileExt) {
continue
}
filenameLen := len(fileInfo.Name())
//文件名中提取一个数字ID,并将其解析为64位无符号整数
//
fid, err := strconv.ParseUint(fileInfo.Name()[:filenameLen-len(walFileExt)], 10, 64)
if maxFid < fid {
maxFid = fid
}
if err != nil {
utils.Panic(err)
return nil, nil
}
fids = append(fids, fid)
}
// 对文件 ID 进行排序
sort.Slice(fids, func(i, j int) bool {
return fids[i] < fids[j]
})
imms := []*memTable{}
// 遍历文件 ID,打开对应的内存表并检查其大小
for _, fid := range fids {
mt, err := lsm.openMemTable(fid)
utils.CondPanic(err != nil, err)
if mt.sl.MemSize() == 0 {
// 如果内存表为空,则跳过
continue
}
// 将非空的内存表添加到结果列表中
imms = append(imms, mt)
}
// 更新最终的最大文件 ID
lsm.levels.maxFID = maxFid
// 返回新创建的内存表和已加载的内存表切片
return lsm.NewMemtable(), imms
}写
二进制文件设计思路
通过上面的介绍可以了解到,sstable是LSM-Tree的一个最基本的组件,sstable本质上是一个文件,接下来就讨论一下文件设计中要考虑的问题。
从简单的 ASCII 文本文档到复杂的数据库,下面是几个文件结构中必要的几个元素,设计者们往往会忽视掉其中一部分。
一个好的文件格式应该至少拥有下面的几个元素:
- 身份标识字符(也被称为 Magic 字符或者 ID 字符)
- 头部验证码
- 版本信息
- 数据位移
这也同样适用于一些从来不会实际存储在一个文件中的数据,比如通过网络传送到移动设备的数据。
身份识别字符
这个叫做 Magic 字符的历史已经很久远了,它通常是一个 2 ~ 4 字符,可能更多或者更少,用来唯一地标识一个二进制文件格式。应该尽量避免和自然语言相近的值,如果文件可能与文本文档混合使用,那使用一个纯 ASCII 字符就是一个不好的选择。随着存储容量的变大,短 Magic 正在慢慢地被长一些的字符串所代替。
身份识别字符在一些非强类型系统中(比如 UNIX )使用,是很有用的。在 Macintosh HFS 文件系统中,是很难将文件和它的创建者类型分开的, 但是在 Windows 下,你只需要重命名它就行了。
在所有的系统中,他们都是有用的:可以确保所读取的文件是你所期望的文件内容。假如一个文件的类型在文件名中缺失,在网络传输中,可能你就要话大量的时间去猜测这个文件的内容是什么。可能你又要说了,我这作为系统“内部使用”就没有必要了吧。但是在开发中,如果作为一个资源被使用的话,当你读取错误的类型的文件时,这将会很快地让你意识到而不是发生了一系列问题之后才意识到。
最帅气(没有之一)的识别字符串当属 PNG 图片文件格式中定义的,它看起来是这样的:
(decimal) 137 80 78 71 13 10 26 10
(hexadecimal) 89 50 4e 47 0d 0a 1a 0a
(ASCII C notation) \211 P N G \r \n \032 \n第一个字符是一个非ASCII字符以防止来自文本文件的干扰。接下来的三个字符则是让人类很显眼的就认出这是一个 PNG 文件。\r\n序列则是一个可以进行一个快速测试,系统会将CRLF转换成CR还是LF。而最后的\n则测试系统会将LF转换成CR还是CRLF。倒数第二个字符是一个CTRL + Z,在有些系统里面,这个作为一个文本文件的结束标记。他不光会检测不正确的文本处理,假如你在 MS-DOS 中打印这个文件,他也能把你从一堆垃圾乱码中解救出来。
ASCII文件格式可以从身份识别字符中获益,因为读取它们的程序可以立刻知道它们是否在读取正确的文件类型。当通过网络传入一个数据流的时候,可以从身份识别字符中识别出传入数据的性质。
头部验证码
你可以用任何字符校验来做,比如 32 位的 CRC,又或者是 128 位的 MD5 哈希。头部验证码紧跟在 Magic 字符之后,用来计算它之后,数据内容(用 数据偏移 标识的位置)之前的内容的校验值。它具有较高的可信度,让你确保你现在所读取的内容与当时写入时的内容是一致的。
很多开发者将内部校验码视为是不必要的,而且他们有信息地认为 TCP/IP 网络是相当可靠的,而且如果你都不能相信你硬盘里面的数据了,你将会遇到很多问题。但是,仍然是有必要进行文件头的校验的。
比如说,存储其实并没有你想的那么稳定。在早些天我收到了很多问题,在 CD 中记录的音乐文件,文本文件和 JPEG 图像都没问题,但是存入的 ZIP 文件却出问题了。而他们没有意识到,只有 ZIP 文件档是存在 CRC 校验的。所有的数据都被损坏了,可能是受损的 SCSI 或者 IDE 数据线所引起的。但是问题那么少,只是因为在很多类型的文件中没有体现出来。你可能不会意识到你的“文本”变成了“又本”。也许你不会意识到你的图片上有些许奇怪的斑点。但是一个 32 位的 CRC 却极少可能会被错误给欺骗过去。
还有一个常见的可能损坏文件的途径是用一个 ASCII 模式的 FTP 传输,他会做行末字符转换(比如,将 LF 转换成 CRLF)。将字节混合或者修改之后可能会引起一些有趣的问题。如果有头部的校验码,你可以立刻知道头部中是否有损坏。如果你可以信任创建这个文件的程序代码,那你可以认为这个头部是可用的,或者说你可以减少你代码执行的检查量。
有一种思想认为,校验码应该放在头部的最后位置,他总是可以在 (OffsetToData - 4) 的位置上找到,而且可以让 CRC 覆盖整个头部,包含 Magic 字符。虽然测试一遍它是冗余的。但是更重要的是这样可以让他作为网络传输的头部。你可以计算 CRC 在你输出了头部字节之后,而不用将插入位置回移到前面去填写它。通常来说,文件头很小,不需要折中类型的处理,但是一定要记住。
版本信息
这应该很明显是一个有必要的字段。应用和文件格式随时间不断迭代,而且也很需要确定一个文件的内容是否可以被读取。有两种基本的方法,序列和主/次。
序列方法用一个简单的值,通常用一个字节存储。数字从0或者1开始,每次递增。程序可以认清和处理它的当前版本或者更早的版本,但是拒绝任何更新的版本。
主/次方法有两个值,主版本和序列方式一样,任何旧版本都可以被处理,但是更新版本不可以。而次要版本对于每一个主要版本来说,都是从0开始。当有新字段被添加的时候,增长。旧版本中不用的字段始终保留,就算过时了不用了也要填充。这个方法比较适合保证向后兼容:较旧的应用程序可以读取较新的文件,因为就算被弃用了的字段在次版本中也是肯定存在的。如果一个文件的次版本更低,程序是知道如何转义它的。如果一个文件的次版本更高,则程序知道所有的字段都被明确地标识出来了,而新加的字段可以直接跳过不读。如果一个文件被重新设计整改了结构,更新主版本以防止旧版本的应用程序会读取新版本的文件。
文件版本号不应该跟程序版本号进行绑定,也不用画蛇添足地加额外信息,比如1.3.5d1。一个或者两个稳定增长的值就足够了。
如果你不想显式地显示出版本号,比如在 PNG 文件中,就用了一种叫做块(chunk)的东西。如果数据格式需要被修改,则块类型的名称会被修改。整体的文件结构不会改变,版本数字被有效地内嵌在块名中(或者在块本身内)。这种方法只在你确信整体文件结构不会被改变时才有用。
有些文件格式会包括一个最小程序版本的数字。这个听起来有点像把马车放在马前面:应用程序最有能力决定是否处理给定的文件格式。文件格式版本应该存储在程序中,而不是其他地方。这个调整是为了保证版本的向后兼容,因为它允许文件格式设计者告诉程序它们是否可以读取这个文件。最好还是交给上面描述的主/次方法来处理。
数据位移
这个字段的优势并不会立刻体现出来,直到哪天你在考虑向后兼容的时候。一个旧的程序可以读一个新的数据文件,因为他知道如何去寻找他需要的字段,跳过不需要的字段。这个位移值告诉程序如何跳过不需要关心的头部字段。
这个偏移值应当是基于文件最开始进行测量的。这对于真实文件(SEEK_SET)和内存缓冲区(将 char* 与位移相加)进行计算都是更简便的。
你可能会试图用这个数字作为版本号。比如,Windows 中使用 sizeof() 来确定多种类型的结构,比如位图。请不要这样做。这会让你进入一种只能不断地把你的文件变大的情况。这对于 Windows API 结构来说很合理,因为他要保证多个版本的二进制兼容性。除非你需要始终向后兼容,否则这在设计上是个错误的决定。
这个属性对于一个 ASCII 文件格式是一个不需要的,在一个边长的头部后面有点显式地在说“数据从这里开始”。
其他字段
有些格式有一些复杂的结构。它们可能有很多个数据区域,每个数据区域有一个偏移值,或者是有一个链表。这些字段是从文件头部还是放入那些区块的头部就取决于设计者你了。
有一个字段你非常值得你去考虑,就是长度字段。对于一个磁盘中的文件,数据的长度被隐式地被文件长度所表示。但是,如果内嵌长度将会让你检测到文件是否不经意之间被修改了(比如从网络上下载的文件),对于通过网络流传输的数据,这点也是很重要的。
其它考虑
结构输出
使用 C 的结构直接进行读写是非常有吸引力的。通过名字访问比较便利,而且可以使代码最小化。
Stop,从历史上来说,这是一个非常糟糕的主意。因为结构的填充和组织随着平台、编译器、甚至不同版本的相同编译器不同会有不同,统一 C 的编译器和明确使用progmas可能可以大部分地解决这个问题,但是要保持最好的兼容性,你还是单独写入它们会保险一点。
使用标准的 libc 缓冲的 I/O 方法(fopen、fread、fwrite、getc、putc)或者使用缓存的 C++ iostream。可能会感觉每个字节调用getc或者putc会比较慢。但是请记住,这些宏在处理一个缓冲区的数据时是很小的。读取数据到一个缓冲区然后你自己再转义不会让你收获多少便利,反而会严重影响代码的清晰度。
有一个常见的错误,一定要避免,当你写 C/C++ 时,写成:
unsigned short val = getc(infp) | getc(infp) << 8;这里遇到的麻烦是,不是所有的编译器都用相同的顺序处理参数,所以你不知道第一个getc()会被先运行还是放到第二位。(ANSI C 中对于这个有定义,但是你不能确保它的实现是遵照 ANSI C 的),把他们分开十分简单,而且编译之后也肯定都是正确的顺序。
在进行一系列的getc()和putc()之后,不要忘了检查feof()和ferror()(以及其他类似的函数)。
低字节序和高字节序
也就是 Little-Endian 和 Big-Endian,这里最好的建议是使用和数据使用者大体相同的格式。如果你写的文件将主要在80x86机器上使用,使用低字节序。当读取数据的时候,你需要选择假设你运行在低字节序机器或者是写可移植的代码。在前者的情况下,你可以一次抓取 2 ~ 4 字节数据,并将其填充入一个整型。在后者的情况,你需要一次读取一个字节,然后进行适当的排序。如果你读取任何东西都通过小函数(Read16LE来读取 16 位的低字节序值),你可以封装你的(非)可以执行问题。
文件数据的校验值
将一个 CRC 放入文件数据比放在文件头部更值得去做。CRC 最好是放在一个数据块的结尾。这让你可以在一个流中写入数据,而不需要回滚位置填入 CRC,对于网络传输数据来说尤其重要。
参数跟文件头部的校验值差不多,但是文件头部要比数据区小得多。
文件结尾标志
文件更改可能会发生在通过网络传输数据或者磁盘产生坏道。你的程序可以通过以下途径检测出这些修改:
- 拥有一个完整文件的 CRC。最可靠,但是性能最差。
- 在头部拥有一个完整的文件长度。读取的时候终止于满足长度,而不是到EOF。如果你不立刻读取整个文件,则跳转位置到
(length - 1),然后尝试读取一个字节。 - 添加一个清楚的结尾标示符。跳转到文件尾,然后读取它。这个文件长度可以从文件头部得到或者从文件系统得到(使用
fseek到SEEK_END)。
如果你在将一个大文件直接在内存中映射到多个线程地址空间,而且不想花大量的时间去进行整个 CRC 的校验,用一个文件位标识是一个非常值得考虑的方法。
文档说明
如果你穿件了一个二进制文件格式,文档记录每一个字节的意义。比如:
All values little-endian
+00 2B Magic number (0xd5aa)
+02 1B Version number (currently 1)
+03 1B (pad byte)
+04 4B CRC-32
+08 4B Length of data
+0c 2B Offset to start of data
+xx [data]ASCII 文件格式可以自行记录,如果你在文档中定义了注释。创建一个默认的使用大量注释的配置文件,然后在你的代码树中保存下来。
4.SSTable
1.LSM要将整个skipList的数据序列化到磁盘上的sst文件上。首先数据在跳表中已经是以二进制的形式,当内存中的数据到达一定阈值时,就要把跳表大byte数组中的二进制数据写入到磁盘的SST文件中。
作为一个文件,需要支持一系列的文件操作
// blockList 存储了一系列的数据块指针。
blockList []*block
// index 保存了数据的索引信息。
index []byte
// checksum 保存了数据的校验和,用于验证数据的完整性。
checksum []byte
// size 表示数据的大小。
size int5.MANIFEST
Manifest 文件是一个用于存储sst所属层级关系的元数据文件,当数据库重启时,需要读取该文件用于恢复层级关系的元信息。其次每次flush或者merge了sst文件后都需要变更Manifest文件。
MANIFEST的必要性
是否可以
数据库事务
1.事务的4大特性
原子性:
一个事务要么全部成功,要么全部失败,如果中间有某个操作执行失败,则数据库回滚到事务执行前
由undo—log来保证,它记录了回滚的日志信息,回滚时会撤销已经执行的sql
一致性:
事务开始前和结束后,事务的完整性不能被破坏(比如你只有200,不能取出300)
一致性由其他三大业务来保证,代码也要保证业务上的一致性
隔离性:
允许多个并发的事务同时对数据库进行读写操作,可以防止多个事务交叉读写是引发的问题
隔离性由MVCC保证
持久性:
事务一旦提交,对数据库的改变是永久性的,即使其他操作出现问题或数据库发生故障,数据也不会丢失
持久性由undo+redolog保证,mysql在修改数据时会在内存和redolog里同时记录这次操作,如果发生意外,由log回滚
2.事务在并发环境下的异常现象
2.1脏读
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
Time事务 A事务 BT1开启事务T2开启事务T3查询账户余额为1000元T4汇入1000元,当前余额为2000元T5查询账户余额为2000元T6提交事务T7撤销事务T8查询账户余额为1000元
2.2不可重复读
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两 次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
Time事务 A事务 BT1开启事务T2开启事务T3查询账户余额为1000元T4查询账户余额为1000元T5汇入1000元,账户余额为2000元T6查询账户余额为2000元T7提交事务T8
- 3幻读
所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行(就是之前不存在的行)。
Time事务 A事务 BT1开启事务T2开启事务T3查询账户 ID > 2的账户总数 = 10T4插入一个账户,账户 ID = 100T5提交事务T6查询账户 ID > 2的账户总数 = 11T7提交事务T8
2.4丢失更新
而如果两事务同时在对数据进行修改,则会导致另外的问题:丢失更新。
丢失更新是两个不同的事务,在某一时刻对同一数据进行读取后,先后进行修改,就会导致第一次更新的事务,数据丢失。
丢失更新,可以根据产生数据丢失的原因分为两种:
如果事务 A 对数据修改完成,事务 B 对数据修改失败,则需要回滚到事务 B 认为的原始状态,会将事务 A 的修改覆盖。这个被称为回滚丢失。
如果事务 A 对数据修改完成,随后事务 B 对数据修改成功,则事务 B 的数据会将事务 A 的修改覆盖。这个被称为覆盖丢失。
5回滚丢失
A事务撤销时,把已经提交的B事务的更新数据覆盖了。这种错误可能造成很严重的问题,通过下面的账户取款转账就可以看出来:
Time事务 A事务 BT1开启事务T2开启事务T3查询账户余额为1000元T4查询账户余额为1000元T5汇入100元把余额改为1100元T6提交事务T7取出100元把余额改为900元T8撤销事务T9余额恢复为1000 元
- 6覆盖丢失
A事务覆盖B事务已经提交的数据,造成B事务所做操作丢失:
Time事务 A事务 BT1开启事务T2开启事务T3查询账户余额为1000元T4查询账户余额为1000元T5取出100元把余额改为900元T6提交事务T7汇入100元T8提交事务T9把余额改为1100 元 (丢失更新)
- 快照读和并发写